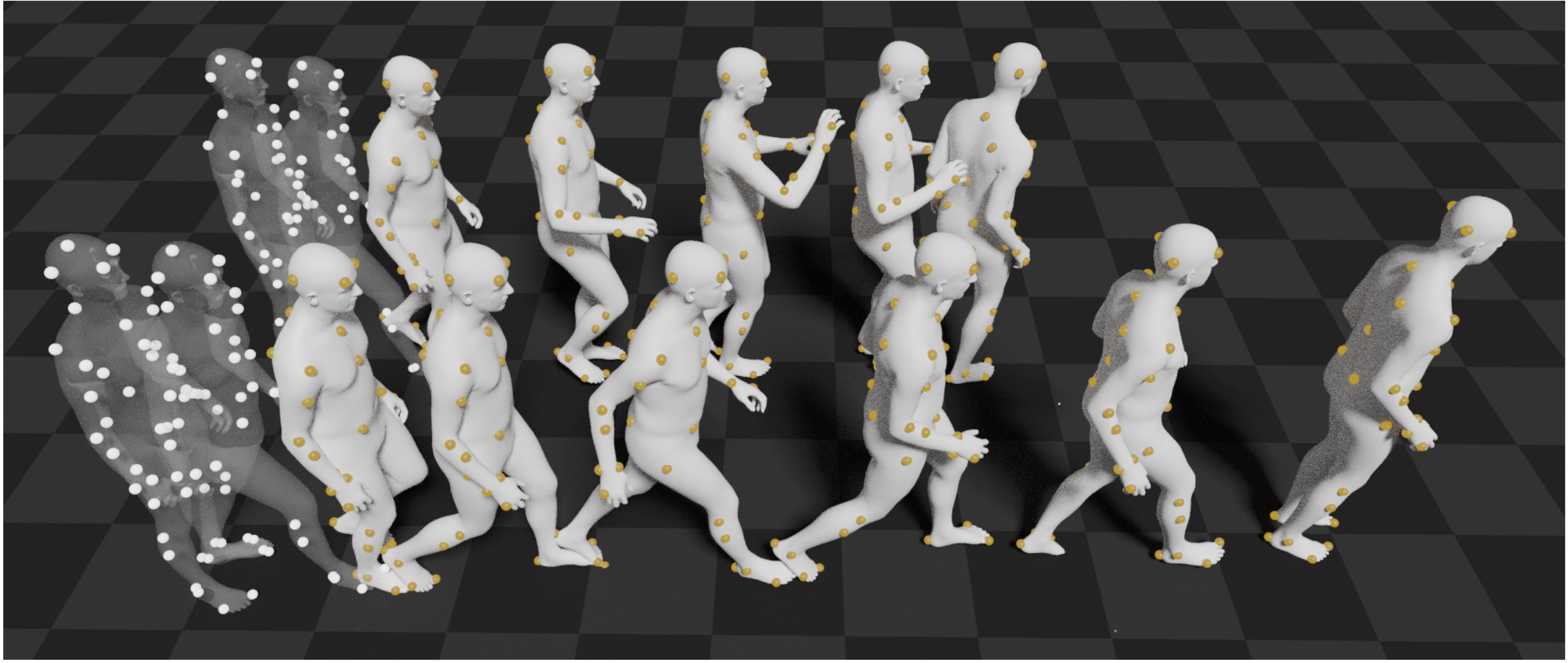
MOJO in a nutshell:
- A body surface marker-based representation. Compared to joint locations, body surface markers contain richer information of the body shape, and provide more body degree-of-freedom constraints. Compared to joint rotations, markers are located in the Euclidean space, which are easier for neural networks to learn.
- A conditional VAE with latent frequencies. With latent frequencies, the generated motion has more high-frequency components and hence looks more realistic. Boosted by DLow as an advanced sampler in the latent space, MOJO produces highly diverse future motions based on the same motion seed.
- A recursive marker reprojection scheme. This scheme is to recover the body meshes from the generated markers during testing. After reprojecting the markers to the mesh template at each time step, it always keeps the markers in the valid body space, and hence can eliminate error accumulation of the recurrent network.
- The Wanderings of Odysseus in 3D Scenes (GAMMA)
- Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO)
- SAGA: Stochastic Whole-Body Grasping with Contact
- EgoBody: Human Body Shape and Motion of Interacting People from Head-Mounted Devices
- Synthesizing Diverse Human Motions in 3D Indoor Scenes (DIMOS)


